This article is about a new Dashbuilder's feature for consuming and visualizing data stored in an ElasticSearch server. ElasticSearch (aka ELS) is a noSQL storage, indexing & search service that provides a distributed, multitenant-capable full-text search engine with a RESTful web interface and schema-free JSON documents. If you want to learn more about it, please visit the ElasticSearch home page.
Dashbuilder is a web based tooling that eases the process of building dashboards . As you might know, Dashbuilder provides a simple API that allows to integrate with any external storage system: the Data Provider API. Since latest 0.3.0.Final release, Dashbuilder adds another data provider for the Elastic Search integration, along with the already existing CSV, SQL and Bean providers. This new one provider allows the users to consume unstructured data from an ElasticSearch server instance at real-time. So you can abstract the data stored in your ELS into a data set structure, and then use all the Data Set API features and power to create your visualizations, as can be done with any of the other data providers available.
The following sections will give you a quick overview of the ElasticSearch integration features. At the end of the article you will also find a tutorial that shows how easy is to integrate Dashbuilder with an ELS server, or as in this example, with the ELK stack, providing an step-by-step tutorial for the creation of a real-time system metrics dashboard. (You can skip the first part of this article if you are only interested following the the tutorial).
 |
| The tutorial's resulting dashboard |
The ElasticSearch data provider
Overview
 |
| Elastic Search Data Provider overview |
Key concepts
| Attribute | Example | Description |
|---|---|---|
| Server URL | http://localhost:9200 | The server URL for your ELS RESTFul API services |
| Cluster name | elasticsearch | The name of the cluster in the server instance |
| Index | expensereports | The name of the index to consume |
| Type/s | expense | The document type/s to consume for the given index |
Once a data set definition is created, Dashbuilder is able to process data lookup calls against the ELS instance and generate a resulting data set, so finally the users can create their visualizations and dashboards using the remote data.
Another important key point about turning ELS unstructured data into structured data sets are the data set columns. ElasticSearch provides its own core data types that are implicitly bind to data set columns by the ELS data provider.
 |
| Data columns binding from an index mappings |
The data columns binding is done automatically by the application when creating a new ELS data set definition. It binds the field name, data type, format and patterns from an ELS index mappings into data set columns with a given name, data type, format and pattern as well.
A detailed documentation about how column binding works and other cool features can be found at the ElasticSearch data provider documentation.
Real-time system metrics dashboard
As you will see in this tutorial, it's really easy to create data set definitions, visualizations and dashboards in Dashbuilder. This demo is intended for non-technical users, as there is no need for coding or having high level technical skills. In a few mouse clicks you will be consuming your ELS data and creating dashboards! :)
Let's see the scenario used for this tutorial and then we will deep into each workflow step for achieving a real-time system metrics dashboard.
Scenario
For this tutorial we have used a well known system metrics reporting and storage environment provided by the collectd daemon and the ELK stack. We decided to use this scenario as it's really easy to setup and you can find lots of documents and articles on the net about it. The main difference with the other tutorials based on the ELK stack is the use of Dashbuilder as the monitoring web application instead of Kibana.
The following diagram describes the environment used in this tutorial:
 |
| System metrics scenario |
- Two computers to be monitored - Computer A & Computer B
- The main server that provides:
- An instance of Logstash server
- An instance of an ElasticSearch server
- The Dashbuilder application
- A single client that consumes the dashboard/s
- Collection and transmission of the system metrics
Both computer A and computer B have the collectd service running, which captures some of the system metrics and send these ones over the local network using TCP and UDP packets - Process and storage of the system metrics
The collectd resulting packets from both computers are processed by the Logstash server and sent to ElasticSearch, responsible for storing all the metrics data in a given index - Consume and visualize the system metrics
Once the client that consumes the dashboard needs to retrieve some metric data, Dashbuilder application performs all the data look-up operations against the ELS storage server, producing the resulting data sets that feed your dashboards and visualizations.
NOTE: In this tutorial, the Logstash server has been configured to store the logs into an index named logstash-logs in the ELS instance, and is not the default one used by Logstash in a clean installation.Once having this or a similar scenario, we are able to consume the computer metrics from the ElasticSearch server and benefit from all Dashbuilder's features.
Keep in mind that Dashbuilder only worries about the ELS server data, it does not care how metrics are collected, processed or transmitted. This means you can store the metrics in any storage supported by Dashbuilder.
Metrics data
Using collectd for generating the metrics provides a huge flexibility and power as it's really easy to install, configure and it supports lots of plugin and metrics. Consider that these metrics are captured by the Logstash server, which process and finally stores each one into the ELS server. So here is the list of fields in the generated logstash's index for each metric that will be consumed by the tutorial:
| Field name | Description |
|---|---|
| @timestamp | The timestamp for the metric |
| host.raw | The hostname that produces the metric (the ".raw" indicates that we are using a multi-field for the host field in the index, for the logstash generated index, it contains the not_analyzed value of the hostname) |
| plugin | The metric plugin (cpu, memory, df, processes, interface) |
| plugin_instance | The instance for the metric for a given plugin |
| type_instance | The type for a given metric (cpu used, cpu free, etc) |
| value | Contains the concrete value for the given metric and type |
| rx | Contains the network packets received in the given interval |
| tx | Contains the network packets sent in the given interval |
Here you can find more information about the collectd plugins and metrics and the collectd input plugin for Logstash.
Let's deep into the step-by-step creation of the system metrics dashboard!
Step by step tutorial
The result of this tutorial is given by a simple three step workflow:

Considerations:
- Dashbuilder web application running at http://localhost:8080/dashbuilder
- ElasticSearch server RESTFul API available and running at http://localhost:9200
- Consider the logstash for the ELS cluster name.
- Consider logstash-logs as the index generated by logstash in the ELS server which contains all system metrics data
Step 1 - Create the data set definition
This tutorial describes just the minimal configuration required for generating a data set with all metrics stored in the ELS server's index. It does not deep into the use of data set filters, column types modifications or advanced attributes and features. Just try and play yourself with it! ;)
At Dashbuilder web application's home click on Authoring -> Data Set Authoring item on top menu:
 |
| Data set authoring menu item |
 |
| New data set button |
 |
| Data provider type selection screen |
 |
| Data provider configuration screen |
 |
| Data provider configuration and data set preview screen |
As commented, this tutorial describes a minimal configuration for creating the data set definition, although is not the best implementation for real production usages.
Tips:
- Just select the columns for your needs
- Modify column types for your needs
- Add initial filters when consuming the data set from several indicators
- Consider data set refreshing
- Do not create just one data set definition for your metrics indicators, create different ones for different metrics and hosts.
- More information can be found at the previous Data set authoring article.
As for this tutorial, just click on Save button to store your data set definition and make it available for creating the dashboard's visualizations.
After save, you should see the new "All system metrics" data set definition in the explorer's list:
 |
| Data set explorer view |
Step 2 - Create a dashboard
To create or navigate through the existing dashboards, use the Dashboards top menu item.
Click on Dashboards -> New dashboard:
Click on Dashboards -> New dashboard:
 |
| Dashboards menu |
 |
| New dashboard popup |
At this point you can create as many displayers as you need, but before starting to create the displayers, you first should think about what you want and what you need.
For this tutorial consider the resulting dashboard's displayers and layout used as the following picture describes:
 |
| Displayers and layout for the dashboard |
- The dashboard will have 5 displayers
- On left side it will have 3 metric displayers to show current memory, cpu and disk usage
- On right side it will have an area chart (memory used in last minute) and a pie chart displayer (to show the current servers that are up and running)
- All displayers will have the refresh feature enabled, using a one second interval, in order to display the real-time metrics
- All displayers will show the average value for each metric, as several hosts can be present at same time
- As you will see in the video, the metrics in real environments usually come with some delay produced by network latency, processing times, etc. So all displayers have a time frame filter to avoid this latency on the charts - for this environment we chose a time frame as:
now -7second till now -3second
Considering a maximum delay of 3 seconds for the metrics, and showing last 4 seconds of data for each one.
Next section describes how to use this popup for creating several displayers and have them created in your dashboard, so keep reading! ;)
Step 3 - Create the visualizations
In order to create a new displayer just click on the New displayer button on right side of the top menu:
 |
| New displayer button |
 |
| Displayer editor popup |
This screen has three tabs, in order to configure the displayer type, the source data and other display related properties.
Displayer 1 - Memory usage metric displayer
Let's create our first displayer - a memory usage metric displayer using the following configuration:
 |
| Memory usage metric displayer configuration |
- On tab type, select type Metric
- On tab data, specify the just new created "All system metrics" data set and add the filters (see the above diagram). The filter configuration should look like this:
 |
| Filter configuration |
- On same tab data, set the metric to display using an average function as:
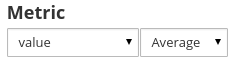 |
| Data set column to display using the avg function |
- Move to display tab and set a title for the chart:
 |
| Displayer title |
- In order to display the value in Gb, go to the Columns section and use the following values for the column attributes:
 |
| Column configuration |
NOTE: For the expression attribute use value / 109 , and for the pattern attribute use #.## in order to show the input values in Gbytes
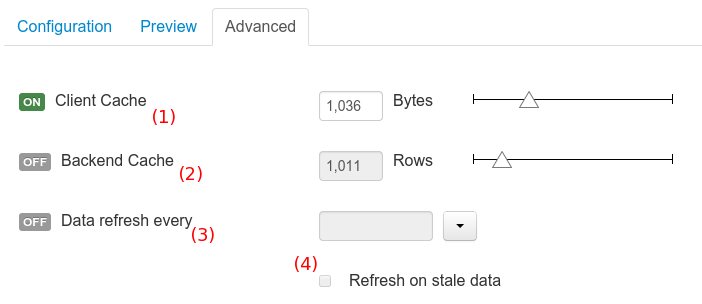
- On same display tab, open the refresh section and enable it using a 1second interval:
 |
| Refresh data every second |
Once the configuration is finished just click the Ok button and the new displayer will be dropped into the dashboard layout:
 |
| Memory used metric displayer |
As you can see, you can create as many displayers as needed and drag&drop them into different dashboard areas. Just click the mouse-left button on the displayer panels's header and drag&drop it into the desired layout's region, when the compass control appears:
 |
| Move your displayers inside the dashboard |
For the next dashboard's displayers, the creation workflow is similar, but just applying the different values on filters and columns. Here is the quick summary of their configuration:
Displayer 2 - CPU usage metric displayer
1.- Apply filters and columns values as:
 |
| CPU usage metric displayer configuration |
3.- There is no need to change column patterns as the values already are in percentage format
Displayer 3 - Free disk space metric displayer
1.- Apply filters and columns values as:
 |
| Free disk space metric displayer configuration |
2.- Set a title for the chart and enable the refresh feature using an interval of 1second
3.- Apply same column configuration (expression & pattern) as the displayer 1.
3.- Apply same column configuration (expression & pattern) as the displayer 1.
Displayer 4 - Memory usage displayer using an area chart
1.- Apply filters and columns values as:
 |
| Memory usage area chart configuration |
3.- Apply same column configuration (expression & pattern) as the displayer 1.
Displayer 5 - Servers pie chart
1.- Apply filters and columns values as:
 |
| Server pie chart configuration |
Video
In order to show the system metrics dashboard in action, here there is quick video that shows how to create some displayers, apply the configurations and move them inside the dashboard areas for generating the final layout.
The environment used for this tutorial was:
Also consider that the metrics data is coming from two different servers (under our control), so we can start, stop and stress them producing the real-time data being monitored by the dashboard.
To avoid long videos it starts with the data set definition, the dashboard and some displayers already created and configured.
The environment used for this tutorial was:
 |
| Environemnt used for the tutorial |
Also consider that the metrics data is coming from two different servers (under our control), so we can start, stop and stress them producing the real-time data being monitored by the dashboard.
To avoid long videos it starts with the data set definition, the dashboard and some displayers already created and configured.