This article introduces the new Dashbuilder's Data Set authoring user interface which allows the user to list, create, update and remove data sets from a web browser. Please note that it's an end-user oriented guide, so do not expect to deep into technical details.
A Data set is one of the main components in Dashbuilder's architecture; all of the different visualizations use Data sets to get the data they need. So if you are not used to the Data set API & architecture, it's high recommended reading this previous article.
Consider the Data set authoring as the name given to the web interface that provides a set of screens to manage your Data sets in a user friendly way. In the following video you can get a quick preview of how the new interface looks like (do not forget to select HD) and how easy is to register a new data set.
 |
| Data Set authoring perspective |
Note: given that point, the use of this authoring perspective gives the user a new and much more easy way for managing Data sets than the default deployment scanner (See section Data set deployment in this article).
Refreshing some concepts ...
To be able to create and edit data sets it's important to get used to the Data set API and some other concepts. This is a quick review (all details in this previous article).
(If you are already familiar with the Data set API & concepts you can skip this section)
(If you are already familiar with the Data set API & concepts you can skip this section)
Data set & Data set definition
The most obvious should be assuming that data set authoring is about the management of data sets, so the underlying model should be a data set. Is it...? Almost true.. but strictly speaking it does not allow the management of Data set instances, it allows the management of Data set definitions.
Remember that a Data set definition is just the representation of a Data set attributes and columns. It provides the information for being able to look up information from remote systems , collect and perform data operations, resulting in Data sets. If looking deeper in the architecture, the definition is a persistent entity that uses the JSON exchange format. Thus you can consider the Data set authoring as a web interface editor for JSON Data set definitions.

Data set definition class members:
- A name and unique identifier (UUID)
- A type. It defines the storage type that provides the remote data to be consumed.
Currently the editor supports Bean, SQL, CSV and ElasticSearch types. These types allow for looking up data from a Java class, a DBMS, a CSV file or an ElasticSearch storage system respectively. - Specific attributes. For example, if using an external DBMS the JDBC url and connection credentials are mandatory user input attributes.
- Data columns. Define which columns will be present in the Data Set when a look-up is performed. See next section Data columns.
- Initial data filter. Minimize the look-up result size by providing a filter.
- Cache and refresh settings. Some other attributes related to client & backend cache sizes and the data refresh policy.
Data columns
Data columns are the name used for the columns of the resulting data set when a look up is performed.
A data column have a unique identifier for the column in the data set and a data type. Dashbuilder supports 4 column types:
- Number - The row values for the column are considered numbers, so you can use the column for further column functions use (sum, min, max, average, etc).
- Date - The row values for the column are considered dates, so you can use the column for further column date related functions (timeframe, intervals, etc)
- Text - The row values for the column are considered plain text. The column cannot be used in any numeric functions neither cannot be grouped (this column will be never indexed in the internal registry).
- Label - The row values for the column are considered text literals. The column can be grouped as the values are considered concrete.
The data set authoring perspective allows the data columns manipulation as you will see in the next sections.
Initial data filter
It's important to remember that a Data set definition can define a filter. It's named initial data filter as it is present in the definition of the data set itself, so all further data displayers and other components that use this definition will be using the subset of data that satisfies the filter conditions.
The goal of the initial filter is to allow for removing from the data those rows that the user does not consider necessary. The filter works on any data provider type.
The goal of the initial filter is to allow for removing from the data those rows that the user does not consider necessary. The filter works on any data provider type.
Note: For SQL data provider type, you can use both initial filter or just add custom criteria in the SQL sentence. The first is more appropriated for non technical users since they might not have do the required SQL language skills.
So it's important to note that you can specify a data filter at two levels:
- In a Data set definition
- In a Data displayer definition
Having in mind that a Data displayer consumes data from a Data set, there are some implications when deciding at which level specify the data filter. For instance, you may have a data set getting the expense reports only from the London office, and then having several displayers feeding from such data set. Another option is to define a data set with no initial filter and then let the individual displayers to specify a filter. It's up to the user to decide on the best approach. Depending on the case might be better to define the filter at a data set level for reusing across all the displayers. The decission may also have impact on the performance, since a filtered cached data set will have far better performance than a lot of individual non-cached data set lookup requests per displayer (cache settings are described at the end of the article).
The authoring perspective
Once familiarized with the API and some other basic concepts, let's see in detail the authoring perspective, its components and the main use cases of the tooling.
The Data set authoring is the name given to the web interface that provides a set of screens to manage your Data sets in a user friendly way.
The Data set authoring is the name given to the web interface that provides a set of screens to manage your Data sets in a user friendly way.
You can navigate to the perspective at Main menu -> Authoring -> Data Set authoring:
The following screenshot shows the perspective screen:
This view defines two panels/sections: the Data set explorer and the Data set editor
Note: For more information about UberFire perspectives and how to use them, please take a look at the official documentation.
 |
| Data Set authoring menu item |
 |
| Data Set authoring perspective |
- Data set explorer
It allows the user to explore and remove current system data sets. See next section Data set explorer.
- Data set editor
It allows to create, read or update a data Set. See next section Data set editor.
Note: For more information about UberFire perspectives and how to use them, please take a look at the official documentation.
Data set explorer
The Data Set explorer is a client side component with the main goal listing all public data sets present in the system and let the user perform authoring actions.
It provides:
 |
| Data set explorer |
- (1) A button for creating a new Data set.
- (2) The list of current available public Data sets.
- (3) An icon that represents the Data set's provider type (Bean, SQL, CSV, etc)
- (4) Details of current cache and refresh policy status.
- (5) Details of current size on backend (unit as rows) and current size on client side (unit in bytes).
- (6) The button for creating, reading or update a Data set. Its behavior is to open the Data set editor for interacting with the instance.
- (7) The button for removing a Data set.
Data set editor
The Data set editor is a client side component that allows the user to create, read or update a data set.
 |
| Data Set editor home screen |
- Clicking on Edit button in Data Set explorer
- Clicking on New Data Set button in Data Set explorer
- Clicking on New data set link in Data Set editor's home screen
Basic creation & edition workflow
The interaction with the editor for both create and edit goals is given by a given workflow with three steps: |
| Data Set creation & edition workflow |
- Data provider type selection
Specify the kind of remote storage system (BEAN, SQL, CSV, ElasticSearch)
- Data configuration - Basic and provider type's specific attributes edition
Specify the attributes for being able to perform the look up to the remote system. These attributes vary depending on the Data provider type selected on previous step.
- Advanced configuration - Table preview & Edition of data set's columns, initial filter, caché and refresh settings
Configure the structure, data and other settings for the resulting data set.
Workflow step 1 - Type selection
Allows the user 's specify the type of data provider for the data set to create.The screen lists all the current available data provider types and helper popovers with descriptions. Each data provider is represented with a descriptive image:
 |
| Data provider type selection screen |
Four data provider types are currently supported:
- Bean (Java class)
- SQL
- CSV
- Elastic Search
Workflow step 2 - Provider specific attributes
Once specified a kind of storage to look up in previous step, the next one is the configuration of the specific attributes to use it.The following picture shows the configuration screen for an SQL data provider type:
 |
| New SQL Data set creation screen |
Similar use for other data provider types:
 |
| BEAN Data set type |
 |
| CSV Data set type |
 |
| Elastic Search Data set type |
- The UUID attribute is a read only field, for further use in remote API or specific operations, as it's generated by the system, but you cannot edit it.
- You can go back to the configuration tab at any time while creating or editing a data set, but if you modify any value on this tab inputs, you have to click on Test button to apply your new changes and perform a new look up. Doing that, you will lose any columns or filter configuration, as the look up result can have different data and/or structure.
Workflow step 3 - Data set preview and advanced settings
At this point, the system is able to perform a look up to the remote system and return a data set. In this workflow's step you can check your result data and customize the structure and the rows for your own interest.This step is presented by using the screens of the Preview and Advanced tabs:
Preview tab
As you can see there are three main sections in this screen:
 |
| Preview tab |
Data set preview
A data table is located in the central area of the editor screen. This table displays the data that comes back from the remote system look up process.
 |
| Data set preview |
You can apply some operations on this table such as filtering and sorting.
Data set columns
You can manage your data set columns in the Columns tab area:
 |
| Data set columns |
Use the checkbox (1) to add or remove columns of the data set. Select only those columns you want to be visible and accessible to dashboard displayers.
Use the drop down image selector (2) to change the column type. This have some implications on further column operations, as already explained on previous sections.
Note: BEAN Data provider type does not support changing column types as it's up to the developer to decide which are the concrete types for each column.
Data set filter
In the Filter tab area you can specify the Data set definition initial filter:
 |
| Data set filter |
While adding or removing filter conditions and operations, the preview table on central area will be updated with the new subset of data.
Note: The use of the filter interface is already detailed in this previous article.
Last settings to configure for a Data set definition are present in the Advanced tab:
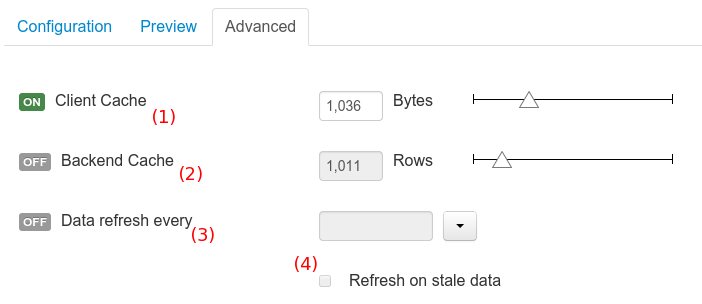 |
| Advanced settings tab |
At (1) you can enable or disable the client cache for the Data set and specify the maximum size (Bytes).
At (2) you can enable or disable the backend cache for the Data set and specify the maximum cache size (expressed in data set's rows).
At (3) you can enable or disable automatic refresh for the Data set and the refresh period.
At (4) you can enable or disable the refresh on stale data setting.
Let's dig into more details about the use of these settings on the following paragraphs (it's recommended the previous reading of this article as it introduces the basics concepts behind Caching&Refresh).
Caching
Dashbuilder is built with caching mechanisms for holding data sets and performing data operations using in-memory strategies. The use of these features have lots of advantages, as reducing network traffic, remote system payload, processing times etc. In the other hand, the user is responsible for the right use of caching and their sizes to avoid hitting performance issues.Two levels of caching are provided:
- The client cache
- The backend cache
 |
| Cachés |
Client cache
If ON then the data set coming from a look up operation is pushed into the web browser so that all the data displayers or other components that feed from this data set do not need to perform requests to the backend, everything is resolved at a client side:
- The data set is stored in the web browser's memory
- The related displayers feed from the data set stored in the browser
- Grouping, aggrtegations (sum, max, min, etc), filters and sort operations are processed within the web browser, by means of a Javascript data set operation engine.
If you know beforehand that your data set will remain small, you can enable the client cache. It will reduce the number of backend requests, not only the requests to Dashbuilder's backend, but also the requests to your backend storage system. On the other hand, if you consider that your data set will be quite big, disable the client cache so as to not hitting with browser issues such as slow performance or intermittent hangs.
Backend cache
It's goal is to provide a caching mechanism for data sets on backend side.
This feature allows to reduce the number of requests to the external storage system, by holding the data set in memory and performing group, filter and sort operations using the in-memory engine.
It's useful for data sets that do not change quite often and their size can be considered acceptable to be held and processed in memory. It can be helpful if the remote system network connection bandwidth has high latency. On the other hand, if your data set is going to be updated frequently, it's better to disable the backend cache and perform the requests to the external system on each look up request, so the external system is responsible for executing group, filter and sort operations using the latest data.
Note: BEAN and CSV data provider types relies on the backend cache by default, as in both cases the data set must be always loaded into memory in order to resolve any data lookup operation using the in-memory engine. This is the reason why the backend settings are not visible in the Advanced settings tab.
Refresh policy
Dasbuilder provides the data set refresh feature. Its goal is to perform invalidation of any cached data when certain conditions are meet. |
| Refresh policy settings |
At (1) you can enable or disable the data refresh feature.The data set refresh policy is tightly related with data set caching, detailed in previous section. This invalidation mechanism determines the cache life-cycle.
At (2) you can specify the refresh interval.
At (3) you can enable or disable refresh only when data is out of dated.
Depending on the nature of the source data there exist three main refresh use cases:
- Source data changes predictable
Imagine a database being updated every night. In that case, the suggested configuration is use a refresh interval = 1Day (2) and disable refreshing on stale data (3), so the system will always invalidate the cached data set every day. this is the right configuration when we know in advance that the data is going to change (predictable changes).
- Source data changes unpredictable
On the other hand, if we do not know whether the database is updated every day, the suggested configuration is to use a refresh interval = 1Day (2) and enable refreshing on stale data (3), so the system, before invalidating any data, will check if it has been updated. If so, the system will invalidate the current stale data set and will populate the cache with fresh data.
- Real time scenarios
On real time scenarios caching makes no sense as data is going to be updated constantly. In this kind of scenarios the data sent to the client has to be constantly updated, so rather than managing the refresh settings for the data set in the Data set Editor (remember this settings affect the caching, and caching is not enabled) you have to define when to update your dashboard displayers by modifying the refresh settings from the Displayer Editor configuration screen. For more information on Displayer Editor and real-time dashboards, please refer to Dashbuilder Displayer Editor & API and Real time dashboards articles.