So what is a data set? Well, basically, it is a set of columns populated with some rows. Another valid definition is: a matrix of data composed by timestamps, texts and numbers values. A data set can be stored into different systems: a database, an excel file, in the memory of an app. or into a lot of other different systems. The good news is that in Dashbuilder there exist an standard way to define a data set, regardless where the data set is stored.
Data set definitions
Every time we want to provide access to a given external data, a data set definition has to be deployed. That definition contains information about:
- where the data set is stored,
- how can be accessed, read and/or parsed, and
- what columns contains and of which type.
Let's take for instance the following data set definition:
 |
| CSV data set definition example |
The definition is a JSON document containing the following properties:
- uuid: A unique universal identifier.
- provider: The method used to get access to the data set. Depending on the selected method a set of extra properties need to be provided, For instance, the filePath is needed in CSV along with separatorChar, quoteChar and escapeChar, in order to parse & read the CSV file.
At the time of this writing we support the following providers:
- CSV, for accessing data stored in comma-separated-value files.
- SQL, for getting data from relational databases through SQL queries.
- BEAN, a Java bean interface for generating data sets directly from Java.
- ELASTICSEARCH, for querying documents stored into Elastic Search indexes.
- isPublic: if set to true means that it can be accessed from the UI editors by anyone with the right permissions.
- columns: this section is used to define which are the data columns we want to be part of the data set, including their type and format. Columns not defined here will be considered as non-existing even if they are part of the data stored. There exist 4 types available:
- date: for date-time values.
- number: for numeric values.
- label: for text context that can be categorized.
- text: for non-categorizable text content (more info at the Data set lookups section).
- pushEnabled
- pushMaxSize
- refreshTime
- refreshAlways: this 4 properties are related to the caching & refresh mechanisms. Will talk about that later on in the Caching & Refresh section.
All the properties listed above are common to all the providers, regardless of its type. Let's take a look at some other data set definition examples:
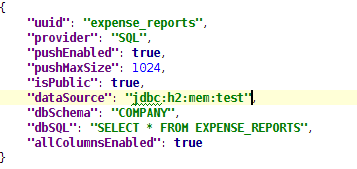 |
| SQL data set definition |
 |
| Java Bean generated data set definition |
The Java Bean provider is an extension mechanism that allows to delegate into a Java class the data set generation. In this case we only have to specify a fully qualified class name plus an optional set of parameters that will be passed to the Java Bean.
 |
| Elastic Search data set definition |
Data set deployment
As we've seen so far, Dashbuilder supports several data set types, and it offers a common mechanism for defining such data sets. Once a data set is defined it needs to be deployed, otherwise it won't be accessible to the Dashbuilder modules.
Dashbuilder is delivered as a web application archive (WAR file). Inside this WAR file there exists a directory called dashbuilder.war/WEB-INF/datasets containing all the data set definitions. Deploying a new data set it's as easy as creating a .dset file containing our JSON definition and copying that file to the deployment directory. Once detected, the data set definition will be loaded and registered automatically in the Dashbuilder data set registry. Changes made to the deployed files will be also detected. When this happens, the entire data set definition is reloaded and any cached data is removed (see the Refresh & cache section below).
The following video, shows a live demo of how to deploy a data set at runtime and how the dashboards can get access to it automatically.
The process described is more intended for technical people. In the next few weeks though, we will be working on a new feature for allowing the end users to edit & deploy its data sets from the UI, the Data Set Editor. We also plan for storing the data sets definitions into GIT repositories through the Uberfire's VFS service as well, to make it easier to share and move data sets between installations.
The process described is more intended for technical people. In the next few weeks though, we will be working on a new feature for allowing the end users to edit & deploy its data sets from the UI, the Data Set Editor. We also plan for storing the data sets definitions into GIT repositories through the Uberfire's VFS service as well, to make it easier to share and move data sets between installations.
Data set lookups
So far so good. The next question is: how the charts in a dashboard get the data they need? Well, once a data set is deployed is ready for receiving lookup requests. For instance:
- Get the total amount of expenses by department
- Get the outstanding sales till the end of this year, grouped by office
- Get the orders received in the last 5 minutes
- Get the travel expenses by employee, only from the sales department
- Get the sales pipeline expected for the next few years
As you can see, a data set lookup request is basically a query over an existing data set, but with some constraints. To be more specific, a lookup request is a sequence of data manipulation operations which produce a resulting data set. The set of operations supported are:
- filter: to get a subset of the whole data set by means of specifying constraints on one or multiple data set columns.
- group: to categorize the whole data sets into groups. LABEL and DATE are the only supported column types.
- sort: to sort the resulting data set by one or multiple columns.
- trim: To limit the maximum number of rows the resulting data set must have.
A lookup request takes an input data set and produces a resulting data set. As illustrated in the following diagram:
 |
| Data set lookup request |
So the way to express some of the examples above as a lookup request is as follows:
- Get the total amount of expenses by department
.dataset("expenses")
.group("department")
.column("department")
.column("amount", "sum")
- Get the outstanding sales till the end of this year, grouped by office
.dataset("expenses")
.filter("date", timeFrame("now till end[year]"))
.group("office")
.column("office")
.column("expectedAmount", "sum")
- Get the travel expenses by employee, only from the sales department
.dataset("expenses")
.filter("department", equalsTo("sales"))
.group("employee")
.column("employee")
.column("amount", "sum")
How this lookup requests relates to the displayers/charts in the UI? The answer is that every displayer, no matter whether is a chart, a table or a selector, performs a lookup request in order to retrieve the data required. Obviously, the set of operations in the lookup request varies depending on the chart type. For instance, a pie chart feeds from a two column data set where the first column is usually the result of a group operation, whereas a table displayer can feed both from grouped and non-grouped data sets and they also permits a variable number of columns in the resulting data set.
For those interested in the internals or just want to see how the Dataset API looks like, I recommend taking a look at the different test cases existing on GitHub.
Using the Displayer Editor users can configure all the data retrieval settings, as shown in the next screenshot.
 |
| Displayer Editor UI |
From this editor, users can define the lookup's filter, group, and sort operations as well as configuring the resulting data set columns. The editor is adaptable, than means that the available settings varies depending on the displayer type selected. Actually, what the application is doing behind the scenes is building and executing a single lookup request over the selected data set.
Data providers
As we described before, every data set definition is linked to a provider: CSV, SQL, BEAN or ELASTICSEARCH. Each data set lookup request is delegated to the proper data provider implementation which is responsible for resolving the request. In case of an SQL dataset, the lookup request is transformed into an SQL query which contains all the lookup's filter, group and sort operations. Thanks to the existing provider interface, Dashbuilder does not have to take care about the lookup request resolution. We can start with a CSV data set definition and move our data to a relational database later on and all our implementations on top of such data set won't break, this includes the dashboards we build and any other client implementations we might have.
The next diagram shows the internal pieces of the Dashbuilder's Data Set Subsystem. Every lookup request received is processed following these steps:
- Get the data set definition the lookup request is referring to.
- Get the provider implementation the data set is linked to.
- Delegate into the provider the processing of the lookup request.
 |
| Data Set Subsystem Architecture |
In the diagram, we can see the DataSetDeployer component which looks for data set deployments & updates. There also exists an especial type of provider called StaticProvider which holds and resolves lookup requests in memory. Unlike the SQL or ELS providers which execute queries against the external data storage, the CSV and BEAN providers are not query processing engines. So what they actually do is to read/generate and register the whole data set into the static (in-memory) provider. This is specially helpful for small data set use cases. For big data scenarios you should definitely consider using an SQL or ELS provider.
When the first lookup request over a CSV data set is requested, the CSVProvider loads, registers and delegates into the StaticProvider the lookup request processing. So the CSV and BEAN providers are just data set loaders since the real processing is carried out by the static provider. The static provider relies on a data set operation engine implementation capable of resolving a sequence of filter, group and sort operations over a data set (further details in the next section).
Caching & Refresh
In the beginning of this article we stated that a data set definition may contain four extra properties:
- pushEnabled (false by default )
- pushMaxSize (1024Kb by default )
- refreshTime (-1=disabled by default)
- refreshAlways (false by default )
All of them are related with the caching & refresh mechanisms. Let's take a look at the following diagram which depicts the Dashbuilder's client/server architecture.
 |
| Client/Server Architecture |
Imagine we have an end user interacting with a dashboard. Let's see what happens when a chart issues a data set lookup request:
1. The DataSetClientServices class receives the request and
2. ... asks the server for the data set metadata which contains the data set definition, size, ...
If "pushEnabled=true" and "pushMaxSize<dataSetSize" then,
3. The whole data set is pushed to the browser.
4. The data set is registered into the ClientDataSetManager.
5. Finally, the initial (and the subsequent) data set lookup request is processed on the client.
If "pushEnabled=false" or "pushMaxSize is not < dataSetSize" then the lookup requests is always processed in the backend.
The push mechanism allows for uploading an entire data set to the user's browser. It applies to any kind of data set, no matter what is the provider type. It's a kind of browser caching mechanism. The main motivations behind this mechanism are the following:
- Improve the performance. Once a data set is loaded all the data set group, filter sort operations performed issued from the UI are resolved without any further calls to the backend.
- Support a pure lightweight client approach. The whole Dashbuilder UI components could be used without the need of the backend layer. Data sets can be registered through calls to the ClientDataSetManager and all the lookup requests will be resolved at a client side. Obviously, this approach is not suitable for large data sets.
The DataSetManager interface is the main entry point for any data set access operation, including the lookup requests. As shown in the diagram, there exists two implementations of the DataSetManager interface, one in GWT and a server implementation in pure Java. Both depend on the DataSetOpEngine, which is a GWT shared implementation that can run on both client & server, this makes possible the ability to process lookup requests in the client side.
So far, so good. However, what if a data set is pushed and the source data is updated? or, for instance, what if a CSV file changes or if a new document is added to an Elastic Search index? Here is when the two remain settings refreshTime & refreshAlways comes into action.
Imagine a database which is updated every night. If we want to get the most updated data then we must set "refreshTime=1day" and "refreshAlways=true". On the contrary, if our data changes every now and then then we must set "refreshAlways=false" which means that the system will ask the database (once a day) whether the data set is outdated before invalidating the current data set.
For SQL/ELS data sets , it makes no sense to set the refresh settings if push is disabled, since all the lookup requests will always be executed against the external storage. Otherwise, for CSV/BEAN it always makes sense, since the contents of the data sets are always loaded and cached in the backend.
For every data set with refresh enabled, an invalidation task is registered into the Scheduler component, as shown in the diagram above. When the refresh interval is reached, the task is executed, a DataSetStaleEvent is fired and any data set cached data (both on the client & backend) is removed.
From the UI perspective we can control in detail when we want a chart to get refreshed. The refresh settings are located in the Displayer Editor > Display tab > Refresh category. One option is to refresh every time a DataSetStaleEvent is received. Another option is to force to refresh every N seconds. This last option is more suitable for real-time use cases.
To sum up, if we know our data is going to change and if we want our dashboards to be notified on every update we must enable the refresh settings. Optionally, if we want to improve our dashboard performance then we can go for enabling the data push feature, but only if our data set is small enough.
In next articles we will talk about real-time dashboards, how to build them and how to integrate Dashbuilder with a non SQL storage like Elastic Search. Stay tuned!
This comment has been removed by the author.
ReplyDelete